强化学习问题回顾
Contents
强化学习概述,从问题定义,到分类,以及经典开源库。
RL问题回顾
强化学习(Reinforcement Learning)本身可以定义为一个广泛的学习问题,学会找到状态(Situation)到动作(Actions)的一个映射关系,以最大化一个数值型的回报(Reward)信号。一个完整的强化学习问题可以用马氏决策过程中的最优控制理论来进行描述。在马氏链中,当前时刻的状态(State) 仅仅与上一时刻的状态有关。如下图1所示,一个智能体(Agent)可以通过某种方式感受环境的状态(State),然后可以通过某一个动作(Action)来改变环境的下一状态。在这个不断交互的过程中,Agent还必须具有一个或者以上的、与此环境状态相关的目标(Goal)。
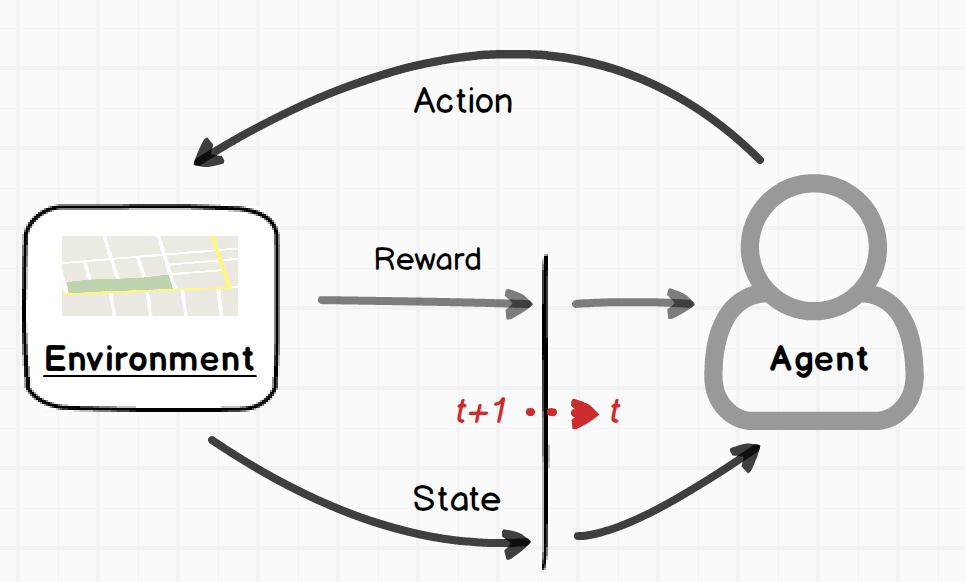
与RL问题相对应的任何求解方法,可以称之为一个强化学习方法。
1. RL的两个重要特征
- 试错搜索(trial-and-error)
- 延迟回报(delayed reward)
可以引出与监督学习的重要区别——评价的方式不同。 监督学习中通过正确的指示(instruct)来进行反馈;强化学习是依靠整个生命周期所选择的动作来进行评价式的反馈。
2. RL系统中的四大主要元素(element)
- 策略(Policy)
定义某个时刻agent的行为,可以看做策略的映射$\pi_(s_t)$。粗略地说,一个策略可以看做是接收到状态到智能体做出动作的一种映射关系,可以用函数或者表的形式来表现。通常来说,策略可以是确定的,也可能是随机的,即可以用条件概率来表示。
- 奖励/回报函数(Reward function)
奖励函数定义了强化学习问题中的目标。它把当前每个状态(或者状态-动作对)映射到一个评价数值,以表现该Agent当前所做事件的好坏程度。
- 值函数(Value function)
奖励函数所表现出的是当前状态或者状态-动作对的立即评价,值函数表征的是对长远意义下的评判。 $V_s$表示当前状态$s$下的累积回报;$V_{(s,a)}$表示当前状态$s$下,执行动作$a$下的累积回报。
粗略来说,值函数可以表示从当前状态开始到未来(long-term),Agent可以收获到奖励的一种累积和。即值函数是对Agent整个生命周期的一种评价。值函数是动作选择的一个标准。
- 环境的模型(model of the environment)
即对该Agent生存环境的行为模仿(mimics the behavior of the environment)。举一个例子,给定一个状态和动作,环境模型可以预测相对应的下一状态和奖励。如果模型已知,强化学习问题可以演化为动态规划问题求解。
3. RL中智能体学习方法的分类
根据强化学习问题中所含元素的种类,其Agent的学习方法,可以分为5大类。
- Model-free
- Model-based
- Actor-critic (Policy + Value function)
- Policy-based
- Value-based
4. 探索与利用的权衡
Trade-off between exploration and exploitation
Agent 需要根据已知的状态、动作和回报的相关信息,来不断获得最大的回报,即利用(exploit)当前已知的知识;另外,Agent 需要探索(explore)一些未知的知识,以期望在未来实现更好的动作。(由于目前的知识往往并不是最优的)
因此,在RL中,利用与探索是一个权衡的话题,目前已提出多种方法来尝试解决这个问题。
- ϵ-greedy action selection(以小概率不贪心的选择方式)
- Softmax action selection(基于Gibbs分布或者称之为玻尔兹曼分布,以概率选择动作)
$$ \cfrac{e^{Q_t(a)/\tau}}{\sum_{b=1}^n e^{Q_t(b)/\tau}} $$
τ>0表示温度(temperature), 高的温度,选择动作近乎平等;温度趋近0的时候,此法接近于贪心选择。
5. Framework/Platform
-
OpenAI gym 是强化学习研究领域广泛使用的一个经典工具包,它主要包含两部分:
- Environments,经典问题的测试集,并提供统一的接口;
- /ScoreBoards/LeaderBoards/Benchmarking,用户算法性能对比的平台,用户可以通过api分享其算法的结果
-
Rllab 与gym 完全兼容,并内置了一些RL的算法,目前rllab项目已停止更新。
-
garage是基于rllab 而来,该项目是为了benchmarking 连续动作控制场景下的DRL算法而建立。
-
Tensorforce: A TensorFlow library for applied reinforcement learning
-
Ray/RLlib 目前RL应用领域sota的框架,构建remote特性;1)具备ms级的task响应,2)以及million的吞吐量。
-
Intel Coach is a python reinforcement learning research framework containing implementation of many state-of-the-art algorithms.
-
OpenAi Baselines SOTA RL算法的集合
Refernece
- Sutton R S, Barto A G. Reinforcement learning: An introduction[M].
- Slides, David Silver. Lecture 1: Introduction to Reinforcement Learning.
Author fooweel
LastMod 2019-04-13